目次
【リクルートインターン参加記】BigQueryの全社的なスロット利用状況を可視化するツールの制作
2024.01.24
目次
はじめに
東京工業大学情報工学系修士1年の服部です。普段は、大学で自然言語処理の研究をしつつ、企業のインターンなどで主にフロントエンドやインフラ領域でのWeb開発をしています。
今回は、2023/10/23(月)〜12/8(金)の7週間にかけて、リクルートのデータスペシャリストコースのインターンシップにデータエンジニア職として参加させていただきましたので、そこで取り組んだ内容について紹介します!
背景
リクルートでは、大量の事業データをGoogle CloudのBigQueryで保持・分析しています。本インターンで私が配属されたチームでは、スロットと呼ばれるBigQueryのクエリ処理に利用される計算リソースを全社的に管理しています。

スロットは予約(Reservation)という仕組みで、決まった容量を管理チームが事前に一括購入し、各開発チームに適切に分配するという方式を取っています。
- この際、全体でスロットをどの程度購入するか?
- 各開発チームにいつ・どの程度スロットを分配するか?
といった事項の判断が必要になるため、各チームの現在の利用状況を正確に把握することはとても重要になってきます。

一方で、BigQueryのコスト最適化も非常に重要な課題です。特にリクルートでは膨大な事業データを取り扱っているため、コスト削減のビジネス的なインパクトは極めて大きなものになります。
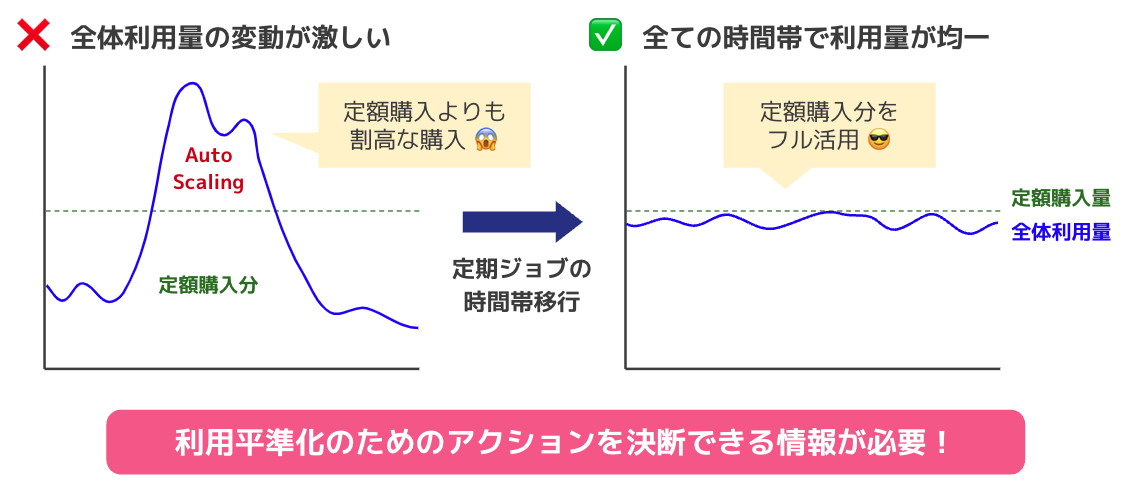
BigQueryのReservationは、一定期間にわたって常に決まった容量を確保する仕組みであるため、定額購入分をフル活用するためには、全ての時間帯で利用量が均一であることが理想になります。特定の時間帯にスロットの需要が高い場合は、自動スケーリング(AutoScaling)機能で追加のスロットをオンデマンドに購入することもできますが、定額購入よりも割高な料金設定であるため、コストの観点からはなるべく利用を避けたいというのが実情です。
各サービスのチームは、決まった時間に定期的なジョブを設定していることが多いです。スロット利用状況を可視化し、適切にジョブの実行時間帯を移行することができれば、全社的により理想的な利用状況に改善していくことが可能だと考えられます。したがって、これらのアクションを判断・実行するにあたって必要な情報をわかりやすく提供することには、高いニーズがあります。
しかし、標準のモニタリング機能は……
BigQueryの利用状況を確認するなら、BigQuery標準搭載のモニタリング機能を使えば良いのでは?と思われるかもしれません。ところが標準のモニタリング機能は、リクルートのプロジェクトの条件下においては、パフォーマンス面で幾つか問題がありました(※)。
(※)BigQueryの利用状況によって、パフォーマンスは大きく変わると考えられます。標準のモニタリング機能があらゆるユースケースで使い物にならない、ということでは決してないはずです!
例えば、以下のような問題が見られました。
- ページの初回読み込みに約10秒かかる
- グループ条件の変更に約10秒かかる
- フィルタ候補(Reservation)を全て取得するのに約60秒かかる
- 表示されるスロット利用量の粒度が粗い
- モニタリングの閲覧権限まわりの設定が面倒
これらの背景から、BigQueryの全社的な利用状況を可視化できる独自のツールを作ろう!という今回のプロジェクトが始動しました。
やったこと
BigQueryの全社的な利用状況を可視化できる独自のツール『LooQ』を作りました!名称の由来は「Looker Studio + BigQuery」からきているのと、なんとなく読み方がギリシャ神話っぽくてかっこよかったからです。
主にBigQueryとLooker Studioを使用しており、インフラの管理(IaC)をTerraform、ソースコード管理やCI/CDをGitHubやdroneで実現しています。

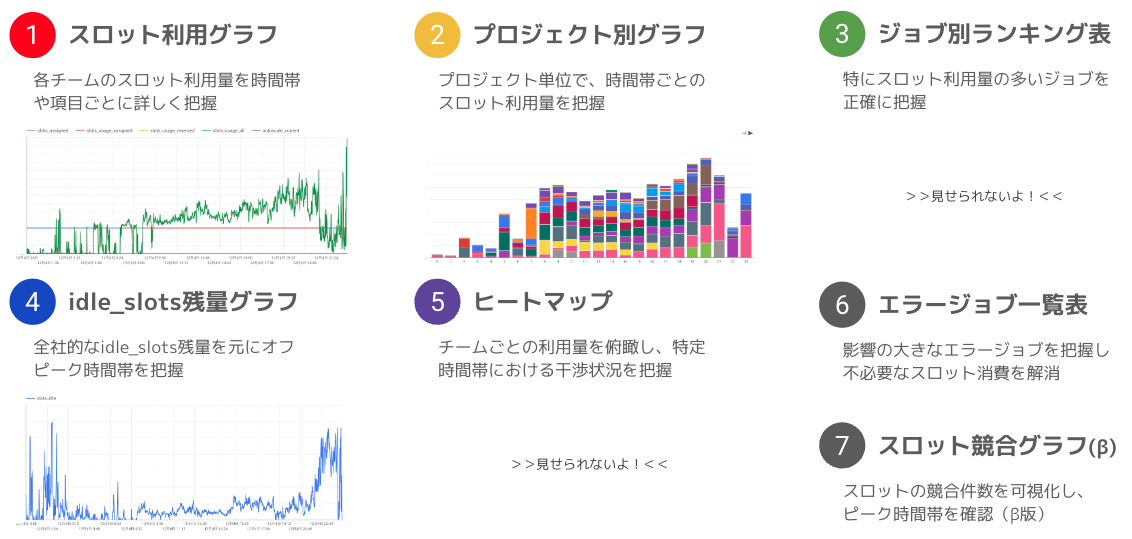
本ツールでは、目的・用途に応じて、全7種類のグラフ・表を用意しました。
(※)この先、数値やプロジェクト名など、一部白塗りで隠している部分があります!
ポイント①:高速&高粒度
本ツール1つ目のポイントは、ズバリ、高速&高粒度であることです。
まず、速度面について、標準のモニタリング機能と比較して、大幅にユーザー体験を向上させることができました。例えば事前のキャッシュが無く、直近1日間の利用状況を可視化する場合、標準のモニタリング機能ではページの読み込みに平均10秒以上、フィルタ候補の取得やフィルタリング操作にも長い時間が掛かる状態でしたが、今回制作したツールではいずれも1秒台以内に完了することができています。

また、粒度面についても、1分間単位でスロット利用量などを集計するようにしたため、より正確な数値を確認できるようになりました。
前述の通り、本ツールは主にBigQueryとLooker Studioを用いて制作しています。具体的にはGoogleが提供しているBigQueryのログデータビューであるINFORMATION_SCHEMAから、可視化に必要な情報のみを2段階のデータセットとして事前に抽出・保存するスケジュールドクエリを設定しています。
INFORMATION_SCHEMAから直接オンデマンドにデータを取得する方法と比較して、情報のリアルタイム性は失われますが、ツールの目的・用途からして、1日おき程度の頻度で更新されるのであればあまり問題はありません。一方で、Looker Studioは事前に必要な情報だけを抽出した小規模なデータセットのみを参照すれば良いため、集計処理は大幅に軽くなります。
また、BigQuery BI Engineと呼ばれるインメモリキャッシュ機能を活用することで、Looker Studioからのクエリ処理をさらに高速化することが可能です。
これらの仕組みを活用することにより、ユーザー体験を重視した快適な可視化基盤を実現することができました。
ポイント②:具体的なアクションを促す実用的な設計
2つ目のポイントは、BigQueryのコスト最適化(=利用平準化)のための具体的なアクションを促す実用的な設計を目指したことです。
今回、BigQueryのコスト削減における効果的な施策の1つは「時間帯ごとの利用を平準化すること」であると判断していました。利用を平準化するためには、それぞれの開発チームが決まった時間に定期的に実行しているジョブの時間帯を適切に移行するというアクションが必要になりますが、その際以下のステップを踏む必要があると考えました。
- まずは自分のチームのスロット利用状況を正確に把握する
- 全社的なスロット利用のピーク/オフピーク時間帯を把握する
- 実行時間帯の移行を計画する or 他チームとの調整・相談を行う
本ツールは、このステップに沿った判断材料を提供できるような可視化を目指しました。
ユースケース:自動スケーリングの削減可能性検討
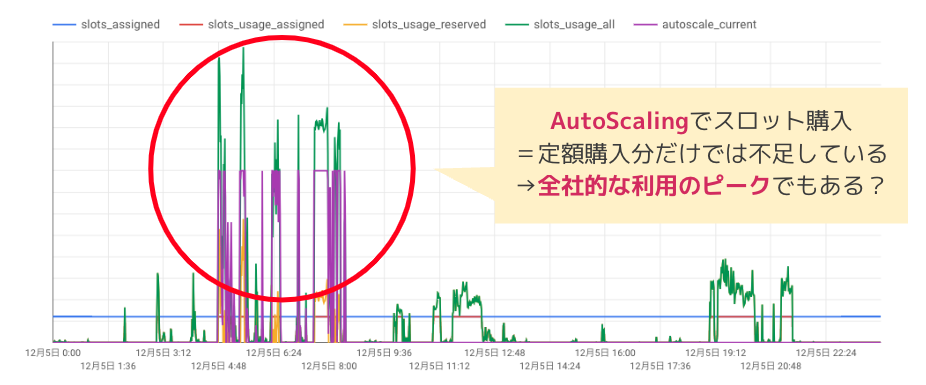
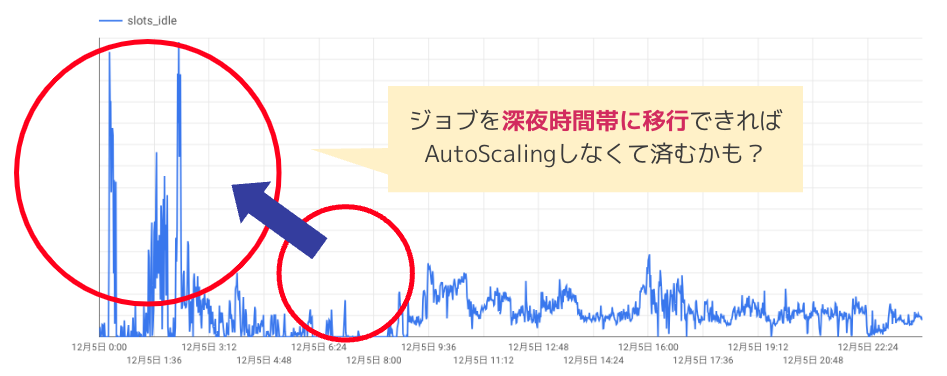
例えば、とあるチームのある1日間のスロット利用状況を「①スロット利用グラフ」で確認してみると、朝時間帯に自動スケーリングを含む極端な利用があることがわかりました。
BigQueryのReservationにはアイドルスロット(idle_slot)と呼ばれる概念があり、特定のチームで定額購入したスロットのうち使われていない遊休スロットがあれば、スロット需要が大きい他のチームに自動的に融通できる仕組みがあります。スロットは、自動スケーリングよりも定額購入分を優先的に使用するため、もし全社的にスロットが十分余っているのであれば、事前のチームごとの配分量によらず、定額購入分のスロットで全て事足りるはずです。それにも関わらず、自動スケーリングが発動しているということは、すなわち定額購入分だけではスロット需要を賄えなかったということであり、全社的な利用のピークでもある、といったことが推測できます。
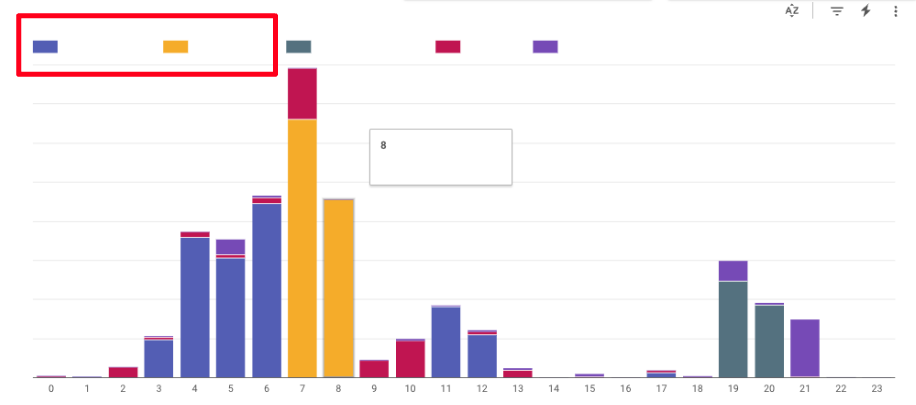
具体的にチーム内のどのプロジェクトやジョブが多くのスロットを利用しているかどうかを確認する際には、「②プロジェクト別グラフ」「③ジョブ別ランキング表」を利用できます。実際に確認してみると、特定のプロジェクトやジョブがどのようなものであるかわかりました。
一方で、「④idle_slots残量グラフ」を確認してみると、全社的なスロットの供給逼迫度がわかります。これによると、全般的に朝時間帯はスロット残量が少なく利用のピーク時間帯であると同時に、深夜時間帯は多少の乱高下はあれど、比較的スロット残量に余裕があることが窺えます。
ここまでの状況から、朝時間帯に自動スケーリングを含む多くのスロット利用がある特定のジョブを深夜時間帯に移行できれば、自動スケーリングをせずに定額購入分のスロットのみで処理を実行できるという可能性が浮上します。
今回は、実際にジョブの移行を実行したわけではなく、またビジネス的な都合で移行が難しいケースもありますが、もし仮に今回の事例で自動スケーリングを100%解消できたとすると、BigQueryの利用料金を年数百万円単位で削減できることが試算できています。これはかなりのビジネスインパクトがありそうです!
備考・検討事項
その他、少し細かな話題や、上記以外に検討した内容を記します。
INFORMATION_SCHEMAの詳細
BigQueryのログデータビューであるINFORMATION_SCHEMAにはいくつものビューが用意されていますが、今回は特に、JOBS_TIMELINE_BY_ORGANIZATION・RESERVATION_TIMELINE_BY_PROJECT・JOBS_BY_ORGANIZATIONの3つを使用しました。TIMELINE系のビューはジョブの消費スロット数などが秒単位で記録されており、時系列グラフなどでの可視化に便利です。一方で、JOBS_BY_ORGANIZATIONでは、ジョブに関するより詳細な情報(実行者のメールアドレス・ステータスなど)を取得できます。
データセットの保存期間
INFORMATION_SCHEMAから情報を抽出する先のデータセットに、どの程度の期間のデータを保存するかどうかには検討の余地があります。データウェアハウス層(1層目)では、本来のINFORMATION_SCHEMAのデータ保持期間(半年間)よりも長い期間を保持しておくことも可能になります。一方で、データマート層(2層目)についてはLooker Studioで可視化できる期間に直接影響しますが、不必要に長期間だとLooker Studioのパフォーマンス低下を招きます。可視化期間と可視化スピードはトレードオフであるため、バランスを模索する必要があります。
今回のケースでは、データウェアハウス層は180日間、データマート層は30日間としました。
total_bytes_processedについて
BigQueryのジョブには、スロット消費数以外に処理バイト数という概念もあり、オンデマンド利用では通常こちらに応じた従量課金額が請求されます。INFORMATION_SCHEMAのJOBS_BY_ORGANIZATIONビューにはtotal_bytes_processedというカラムがあり、集計可能なデータになっています。本インターンでも当初、この指標を用いて「ジョブ処理の真の重さ」を見積もることを検討しました。
しかし、実際にジョブのデータを確認してみたところ、スロット確保数と処理バイト数は必ずしも比例していないことがわかりました。処理バイト数の大小はクエリの性質にかなり依存しており、「処理バイト数は少ないが計算量が多くスロットを多く要求するクエリ」のようなものが存在していると考えられます(おそらく、必要メモリ量は比較的少ないが、計算効率が悪いクエリなど?)。また、total_bytes_processedに記録されるのは「請求対象の」処理バイト数です。ジョブ全体が何らかのエラーで失敗した場合、処理バイト数が請求対象にならず、記録に残らない場合もあります。
以上の性質から、処理バイト数から正確なジョブの処理の重さを見積もり、全社的なスロット需給を判断することは難しいと判断し、今回はこの指標の採用は見送ることにしました。
スロット競合(Slot Contention)
BigQueryがクエリを実行するにあたって、何らかの事情で十分なスロット数を確保できなかった場合、スロット競合(Slot Contention)が発生することがあります。今回のようにReservationを利用している場合、スロット競合が発生するのは、一般にスロット需要が高く供給が逼迫しているタイミングであると推測できます。スロット競合の発生有無についてもINFORMATION_SCHEMAのJOBS_BY_ORGANIZATIONビューから取得できるため、集計したスロット競合の発生数を利用のピーク/オフピークの判断材料に用いるということが考えられます。スロット競合はステージ単位で記録されているため、正確な発生時間帯の集計にはやや高度なクエリが必要になります。
今回のツールでは、β版として簡易的に集計したスロット競合の発生件数グラフを提供しています。
実際のコミット量よりも多くのスロット数がINFORMATION_SCHEMAに記録される場合について
実際にINFORMATION_SCHEMAでスロット利用量を取得し可視化してみたところ、本来利用できるはずのスロット数を大幅に上回る不審な合計量となる瞬間がスポット的に存在していることに気が付きました。クエリの集計ミスではなかったため、Google Cloudのサポートに問い合わせを行ったところ、BigQueryの仕様(クラスタのリソース分配)によるものであるということが判明しました。現状、この問題に対処できる方法がないため、INFORMATION_SCHEMA経由でスロット利用数を可視化する際の懸念事項になるかもしれません。
取り組んだ感想・今後の改善
今回のインターンで取り組んだ内容は、BigQuery特有の仕様は多かったものの、SQLの設計やTerraformによるインフラのコーディング自体はそれほど複雑ではなかったと思います。一方で、
- クエリを実行して不審な可視化結果が得られた時の原因分析
- 何をどのように可視化するべきかの設計
といった部分は難しく感じました。特に可視化項目の設計は、実際の企業やチームにおける業務フローとも深く関連するものであり、何か特定の正解が定まっているというわけでもありません。ある種の上流工程に近いものがあり、技術面とはまた違った難しさを実感しました。
今回制作したツールは、まだ粗削りな部分も多いと思うので、具体的な可視化項目の改善や業務フローの設計は今後の改善点になるかと思います!
インターンシップについて
取り組んだ案件の内容以外にも、今回のインターンでは、恵まれた環境下で様々な経験をさせていただきました!ここではその一部を紹介します。
勤務形態について
自分の場合は、だいたい週3日・20時間弱の勤務で、うち週1日は本社オフィス(グラントウキョウサウスタワー)に出社していました。時給はなんと3,000円!さて、この冬はどこに旅行しようかな……。
インターン生には必ず現場メンターと人事の担当者が1人ずつアサインされます。現場メンターの方とはほぼ毎日ハドルやTeamsで打ち合わせを行い、Slackのチャンネルでも頻繁にやり取りをしていました。
人事の方や、メンター以外の社員の方とも週に合計1〜2回ぐらい1on1(よもやま)を行い、リクルートという会社についてや、キャリアについての理解を深めることができました。
(※よもやま・・・職階や職域にとらわれず気軽に会話や相談をするリクルート独自のミーティング文化)
メンターの方がサポートしてくださる形式のインターンは他にもあると思いますが、リクルートは特に様々なフォローが手厚いと感じました。
他のインターン生との交流
自分が配属されたチームはインターン生は自分1人でしたが、他のチームのインターン生と交流する機会もあり、様々な話で盛り上がることができました。初日や最終日の懇親会のほか、オフィスに出社した有志でランチ会が開催されたりもしていました。
理系で研究にすごく熱心な人から、文系で自主的にプログラミングしている人、まで、様々なバックグラウンドを持った人たちが集結していました。全体的には、落ち着いていて、かつ話しやすい人がとても多かったように思います!
Google Cloud Next Tokyo ’23
インターン期間中に偶然、Google Cloud Next Tokyo ‘23というGoogle Cloudのイベントが東京ビッグサイトで開催されており、インターンの一環として参加することができました。Google Cloudの新機能や今後の展望、各企業のユースケースについて様々なセッションやブースがあり、とても勉強になりました!
個人的には特に、BigQueryとLLM(大規模言語モデル)の組み合わせが面白いと思いました。LLMをSQL文から呼び出して、音声や画像といった非構造化データをテキストやベクトルなどの構造化データに変換し、分析に使用する「AIデータウェアハウス」という概念は、今後よりメジャーになっていきそうな予感がします。
ちなみに会場の中にはQuiz Challengeというブースもあり、4択クイズ集にチャレンジしたところ、オリジナルのポーチやInnovators Plusの1年間ライセンスがもらえたりしました。Innovators Plusは、蓋を開けてみたら思ったよりもかなり色々なクレジットがあって驚きました。今度、Google Cloudの資格試験にでもチャレンジしてみようと思います。


ご飯が美味しい
インターン期間中は、現場メンターの方にたくさんご飯に連れて行ってもらいました。普段は少し手を出しづらい贅沢なランチやディナーをたくさん味わうことができました。食にこだわる日本人たるもの、これほどまでに幸せなことが他にあるでしょうか?いや、ない。




最近リニューアルした、リクルートの社員食堂にも行くことができました。美味しかったです。日替わりでメニューが変わるとのことなので、飽きずに利用できそうですね。
おわりに
本インターンでは、データスペシャリストとして全社的なBigQuery利用状況の可視化に取り組みました。BigQueryやLooker Studioの使い方に詳しくなっただけでなく、データエンジニア・データサイエンティストという職種についての理解が深まる機会にもなりました。データ分析といえば、Kaggle・機械学習・アルゴリズムのイメージが強いですが、実際にはデータ分析をするためのインフラ基盤の構築やクラウド活用の知識も必要であり、様々な技術が身につきそうだと思いました。また、エンジニアリングだけでなく、ビジネスや事業展開の観点から物事を提案する上流工程的な業務に携われる点も面白いと感じました。
最後になりますが、インターンでは、配属先チームのメンターの方をはじめ、様々な方に大変お世話になりました。ありがとうございました!