目次
BigQuery ML を実プロダクトで使うために調査した話
2019.03.27
目次
インターン参加学生の記事です。
京都大学の佐藤です。リクルートのインターンシップに参加し、リクルートグループのとあるサービスの機能改善に携わっていました。
今回改善を担当したのは、リクルートのサービス内の検索機能のランキングアルゴリズムです。ランキングアルゴリズムとは、検索したときに表示されるアイテムの並び順を決定するアルゴリズムのことです。
このランキングアルゴリズムを構成する一部に、アイテムの価格予測モデルがあります。このモデルは、検索クエリとアイテムの特徴量から価格を予測し、予測価格よりも実際の価格が安いアイテムをより上位に表示させるために用いられています。
この価格予測モデルの作成部分をGoogle社の提供するBigQuery Machine Learning(以後BQML)を用いたバッチ処理にしました。その過程でBQMLの使い方を調査し、BigQuery(以後BQ)を使う上で考慮すべき費用を検証しました。 今回は、BQMLの使い方、長所と注意点について書きたいと思います。
やりたいこと
検索クエリのパターンに柔軟に対応した価格予測モデル作成
- 主要な絞り込み検索に使われる項目でアイテムをグループに分割
- グループごとにモデルを作成
- モデルごとにパラメータを抽出
BQMLではSQLを書くように目的変数と説明変数を定義してモデルを作成することができます。学習に使うデータはサブクエリのように書くことができます。説明変数のワンホットエンコーディングはBQMLでよしなにやってくれるので一部の前処理はこちらで書かなくてもすみます。 例えば、アイテムタイプaのグループについて、特徴量feature1~4から線形回帰モデル sample_model を作成するときのクエリは以下のようになります。
CREATE OR REPLACE MODEL `dataset.sample_model`
OPTIONS
(model_type='linear_reg') AS
SELECT
feature1,
feature2,
feature3,
feature4,
price AS label
FROM
`dataset.table1`
WHERE
item_type = 'a'CREATE OR REPLACE MODEL `dataset.sample_model`
OPTIONS
(model_type='linear_reg') AS
SELECT
feature1,
feature2,
feature3,
feature4,
price AS label
FROM
`dataset.table1`
WHERE
item_type = 'a'モデルのパラメータ抽出もSQLを書くように実行できます。 例えば、先ほど作ったモデル sample_model からパラメータを抽出するときのクエリは以下のようになります。
SELECT
*
FROM
ML.WEIGHTS(model `dataset.sample_model` )今回はモデルのパラメータ抽出が目的なので使いませんでしたが、評価と予測も同様に実行できます。 例えば、作ったモデルを使って、アイテム価格の予測精度を取得するときのクエリは以下のようになります。
SELECT
*
FROM
ML.EVALUATE( model `dataset.sample_model`,
(
SELECT
feature1,
feature2,
feature3,
feature4,
price AS label
FROM
`dataset.table1`))作ったモデルを使って、2018年11月分のデータのアイテム価格を予測したときの結果を取得するときのクエリは以下のようになります。
SELECT
*
FROM
ML.PREDICT( model `dataset.sample_model`,
(
SELECT
feature1,
feature2,
feature3,
feature4,
price AS label
FROM
`dataset.table2`))一連の流れをバッチ処理にする方法としてクライアントライブラリとGoogle Cloud SDKの2つが挙げられます。ちなみに、BQをPythonから触るときによく使うpandas.to_gbq/pandas.read_gbqはモデルのスキーマがpandas.Dataframeのスキーマと異なるので使えませんでした。
次に、一連の流れにかかる費用を検証します。
BQおよびBQMLの利用料はSQLで処理したデータの容量によって決まります(詳細はこちら https://cloud.google.com/bigquery/pricing#queries を読んでください)。BQMLはBQとは異なる料金体系(料金体系のURL)を取っていて、端的に言うと約50倍高くつきます。自分の書いたSQLがどれくらいデータ容量を使うかはWeb UIから確認できます。 (Web UIから確認できる:右下の142.65(ML)のところ)
以上がBQMLを使う上での一連の流れになります。
続いて、BQMLの長所、注意点とそれに対しての私なりの工夫について書きます。
長所
クラウド上で機械学習モデル作成が簡単に実現できる
データの抽出、前処理、モデル作成がひとつのクエリで完結するので非常に便利です。パラメータの抽出まで含めてもすべてクラウド上で実行することができます。
注意点
BQにしては時間がかかる
BQの長所として巨大なデータ操作が高速である点があげられますが、個人的な感想としてBQMLはBQほど処理の高速さに感動することはありませんでした。また、本ブログの執筆時ではオンライン学習に適した機械学習手法がサポートされておらず、モデルの更新頻度が高い場合にはあまり向いていません。
従量課金
パラメータ抽出、予測、評価はBQと同じ料金体系ですが、モデル作成はBQとは異なる料金体系なので工夫が必要になってきます。
工夫したところ
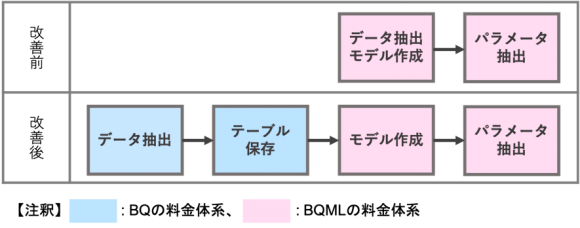
今回のプロジェクトでは、いくつかモデルを作って試算したところ、価格予測モデルを一通り作成するために、10万円以上かかることが判明しました。そこで、モデル作成のどの要素が課金に繋がっているのか仮説を立て、対策を考えました。
まず、サブクエリ内のWHERE句で絞り込む対象を変えアイテムの多いグループとそうでないグループの両方でモデルを作ってみたところ、モデル作成に使うサブクエリから出力されるデータ量の寡多に関わらず料金が同じであることがわかりました。ここから、BQMLではサブクエリ内のWHERE文で絞り込む前の読み込んだカラムのデータ量で課金されるのではないかと考えました。
そこで、モデル作成の前に必要なデータを抽出しBQ内に新しいテーブルをつくりました(BQの料金体系)。次に、そのテーブルを参照してモデルを作ることにしました(BQMLの料金体系)。BQMLの料金体系でやることを最小限にすることでコストを抑えようという話です。
この方法によって、99.5%の費用削減に成功しました。
その結果、BQMLを安価に利用可能になり、BQMLによって価格予測モデルを定期的に更新し続けることは、費用対効果の点で十分に現実的だということがわかりました。
終わりに
本インターンシップを通して、大規模なデータを対象にしたモデル作成をバッチ処理にするという、趣味の開発や研究ではできない経験ができました。なかでも、費用を検証しながら開発することには難しさとやりがいを感じました。
また、BQMLという、比較的新しいツールを試行錯誤しながら使ってみたこともいい経験になりました。
この投稿がBQMLを使ってみようか迷っている方や使い方がわからない方にとって少しでも参考になれば幸いです。
出典:RECRUIT TECHNOLOGIES Member’s Blog
(エンジニアコースのインターン生・佐藤さんが書いてくださいました)